Social Listening
In popAI project, the European Citizen Action Service (ECAS) is in charge of bringing the citizens’ perspective in understanding how people perceive AI tools being employed by law enforcement agencies (LEAs). To achieve this goal, ECAS employs a multi-layered approach, combining both proactive tools (the crowdsourcing platform that you can still contribute to) and passive ones, like the social listening.
As mentioned, social listening is a way of monitoring web content for key themes and discursive trends. It is used by marketing professionals for their business purposes. Using mainly data from social media platforms, this allows them to then target users with very specific interests, maybe even specific people themselves for future campaigns.
In the context of popAI, ECAS is conducting social listening in order to gather and assess the diverse citizen attitudes towards AI and policing. It should be noted that ECAS makes use of ethical social listening, which does not collect any data about the individuals, but is only interested in the content of the messages or conversations themselves. This prevents any possible biases about the data and respects the privacy of the people who voiced the opinions.
Methodology
To analyse data, of course, one must first get it from somewhere. For the purposes of popAI social listening, ECAS researchers use the CommonCrawl database for the years 2013-2021, which “crawls” and records the internet – blogs, publications, research papers, news articles and everything else except for social media.
They then cast a net of keywords that identify AI tools (e.g biometric identification) and aspects of possible concern about them (e.g. privacy, accountability, etc.). Any opinion that is present in the CommonCrawl database and matches these keywords becomes part of the dataset and is filed accordingly.
Up to this point, relevant results have been gathered, thus allowing to track the volume of conversations that happened over time, due to their timestamps. What is missing??? The sentiment. How do we understand if an opinion is positive, negative or neutral and how can we make conclusions on the overall disposition of the public towards the topic of interest?
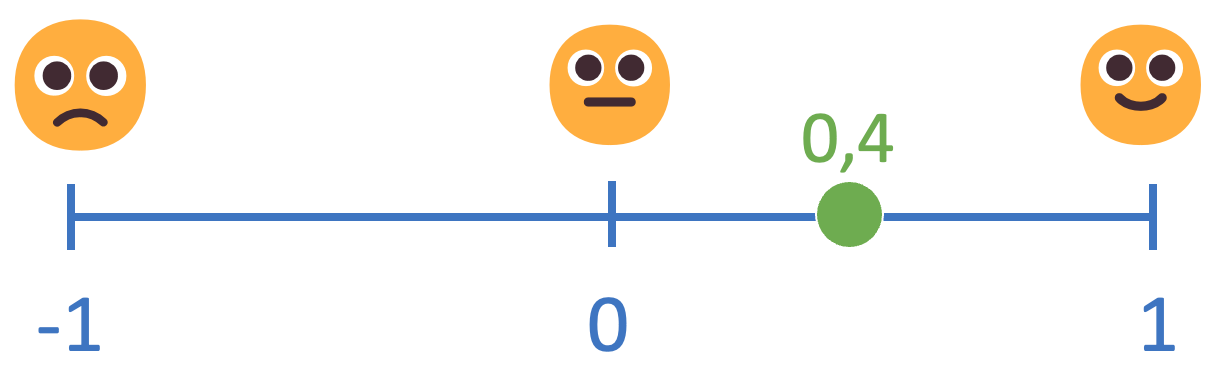
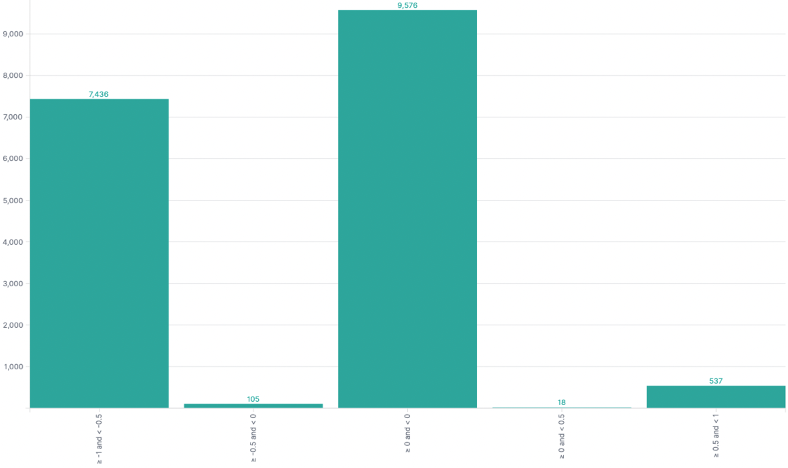
For this purpose, a language model was used. Such language model was trained on millions of texts to determine sentiment in numerical format, from -1 (the most negative) to 1 (the most positive) and decimal numbers in between.
Searched AI tools
- Biometric identifiers
- Cyber Operations
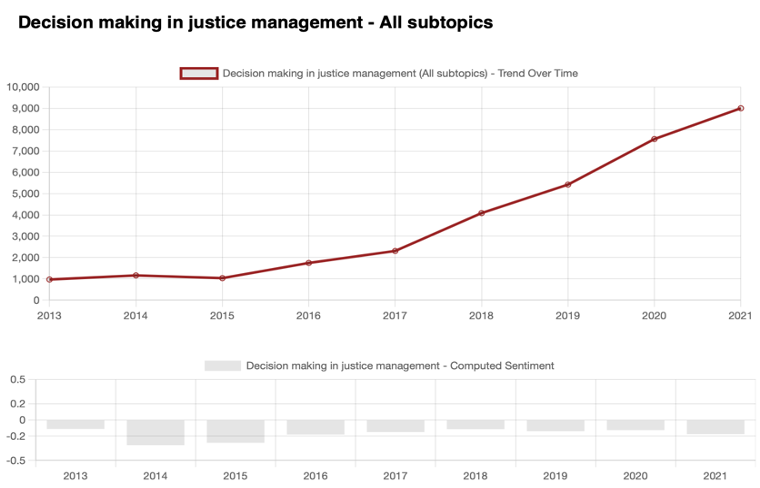
- Decision making algorithms in the justice system
- Police hacking
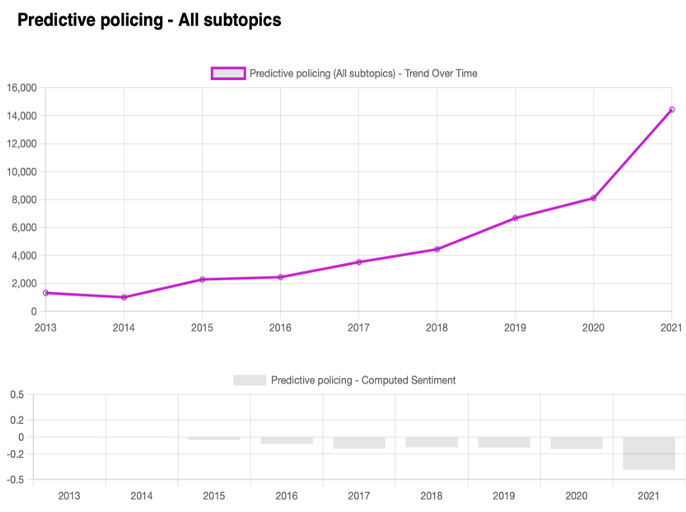
- Predictive policing
For each of those tools, we wanted to find out the sentiment as they relate to possible concern to citizens

Possible citizen concerns
- Discrimination
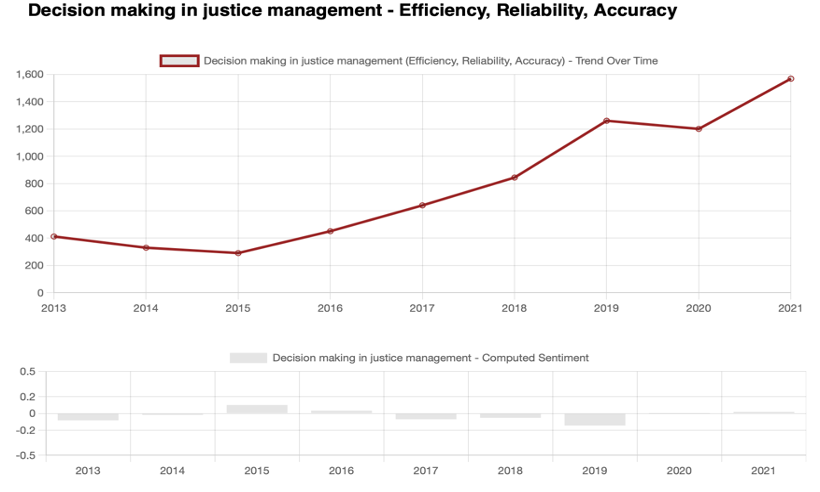
- Efficiency, Reliability, Accuracy
- Legitimacy
- Privacy
- Transparency and Accountability
Results
The social listening activity allowed to gather several information about citizen perceptions and concerns related to the use of AI-based technologies in the security domain. The final report (available at the end of the project) will present all the results in a comprehensive fashion; this section reports the most significant and interesting results that have been gathered in four groups.
Topics generating most online conversation
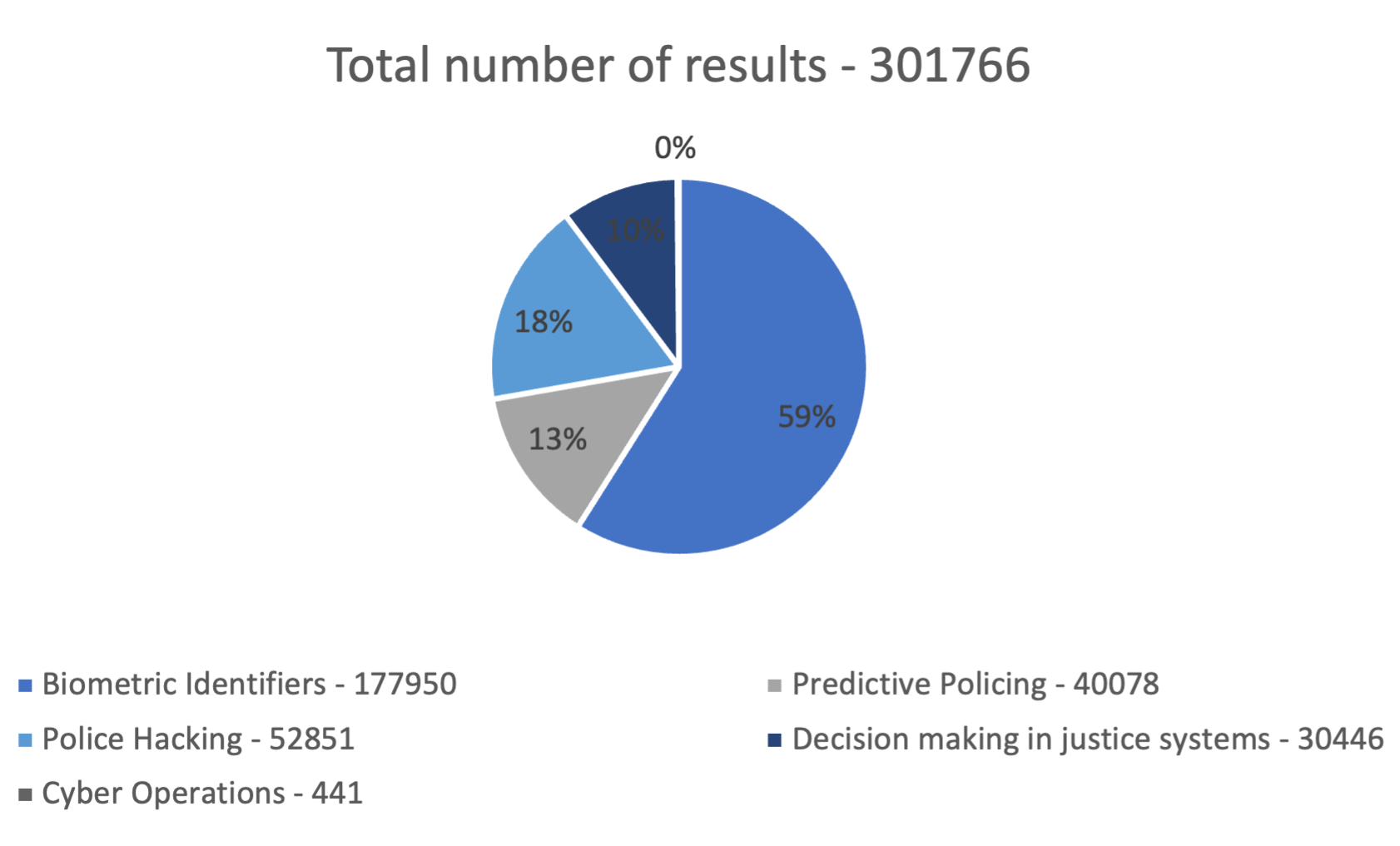
When it comes to the topic generating most conversations online, there is an uncontested winner: Biometric Identifiers, or biometrics.
Biometric Identifiers gained more than 50% of the total results, followed by police hacking and predictive policing. Cyber operations brought a total of 441, which is statistically irrelevant and is below 1% of all results.

Biometric identifiers are unique and measurable characteristics that allow to label, identify and authenticate individuals. They are two types of biometrics:
- Physiological biometrics employ physical, structural, and relatively static attributes of a person (e.g. fingerprints, pattern of their iris, contours of the face, or geometry of veins).
- Behavioural biometrics establish identity by monitoring the distinctive characteristics of movements, gestures, and motor-skills of individuals.
The social listening activity gave the popAI project valuable insight into the feelings of people towards artificial intelligence being used by law enforcement agencies. Taking this knowledge, we can now move to the next phase – asking citizens about their ideas on how these concerns can be fixed. Based on the crowdsourcing questions and the data from the ethical social listening, we want to hear citizen’s solutions and recommendations in three key areas:
This knowledge is crucial and preliminary to move to the next phase – asking citizens possible solutions , thus providing their ideas on how these concerns can be fixed.